Web-Scraping mit KI - intelligentes scrapen mit firecrawl
Web-Scraping hat durch den Einsatz von Künstlicher Intelligenz eine neue Dimension erreicht. Während traditionelle Methoden wie cURL nur rohe HTML-Daten liefern, ermöglichen moderne KI-gestützte Tools wie Firecrawl und SerpAPI das intelligente Extrahieren und Strukturieren von Webinhalten.

Wer kennt es noch, man bekam die Aufgabe sich mit Thema XY zu beschäftigen und sollte dazu 100 passende Kontakte raussuchen. Wie viel Zeit hat man damals damit verbracht sich durch verschiedenste Internetseiten, Subseiten und Google-Seiten zu klicken - wahrscheinlich viel zu viel.
Was ist scraping?
Scraping (auch Web- oder Screen-Scraping) bezeichnet das automatisierte Auslesen und Speichern von Informationen aus Websites oder Online-Diensten mithilfe von Programmen oder Skripten, um die gewonnenen Daten weiterzuverarbeiten oder auszuwerten.
Scraping ist beispielsweise ein zentraler Bestandteil aller Suchmaschinen, die es nutzen, um Websites zu indexieren. Auch die meisten Vergleichsportale arbeiten mit Web-Scrapern, um Daten automatisiert zu sammeln und auszuwerten.
Ist scraping illegal?
Kurz gesagt: Nein, grundsätzlich ist Web-Scraping nicht verboten. Dennoch sollte man die Situation im Einzelfall sorgfältig prüfen, da sich das Vorgehen schnell in einer rechtlich problematischen Grauzone bewegen kann – etwa, wenn die gescrapten Daten hinter einem Login liegen oder die Nutzungsbedingungen der Website das Scraping ausdrücklich untersagen. Zudem muss stets darauf geachtet werden, dass die Verarbeitung der Daten im Einklang mit der DSGVO erfolgt.
Modernes scraping mit KI
Die grundlegende Frage für modernes Web-scraping ist immer: “wofür?”. Denn mit den aktuellen Möglichkeiten ist so gut wie alles möglich. Für modernes Web-scraping gibt es eine vielzahl an Tools, um den Prozess zu optimieren.
Scraping mit cURL
cURL ist ein sehr vielseitiges Open-Source-Werkzeug, das sowohl als Kommandozeilenprogramm („curl“) als auch als Bibliothek („libcurl“) verfügbar ist. Es dient dazu, Dateien zu oder von einem Server im Internet zu übertragen und unterstützt dabei eine große Zahl unterschiedlicher Netzwerkprotokolle.
Zwar kann cURL genutzt werden, um auf niedriger Ebene Websites auszulesen oder einfache Scraping-Aufgaben durchzuführen, jedoch ist es dafür nur bedingt geeignet. Im Vergleich zu modernen Web-Scraping-Tools ist cURL in seiner Funktionalität eingeschränkt und nicht speziell auf die Verarbeitung komplexer Webseiten (z. B. mit JavaScript) ausgelegt. Die einfache Ausgabe der HTML-Datei ist mittlerweile nicht mehr ausreichend.
Moderne Tools für Web-Scraping
Ein großer Nachteil klassischer Methoden wie cURL ist, dass die Ausgabe zwar den HTML-Inhalt einer Seite liefert, jedoch nicht strukturiert oder direkt weiterverarbeitbar ist. Um aus diesen unstrukturierten Daten nützliche Informationen zu gewinnen, sind zusätzliche Parsing-Schritte (z. B. mit BeautifulSoup oder Regex) nötig – ein Prozess, der schnell komplex, fehleranfällig und zeitaufwendig wird.
Moderne Tools wie FireCrawl oder SerpAPI gehen hier einen Schritt weiter. Sie automatisieren nicht nur den Abruf von Webseiten, sondern liefern strukturierte, bereinigte und häufig bereits semantisch aufbereitete Daten zurück. Dadurch entfällt ein Großteil der manuellen Datenaufbereitung.
FireCrawl konzentriert sich auf das intelligente Durchsuchen und Extrahieren von Webinhalten. Das Tool kann ganze Websites oder bestimmte Seitenabschnitte automatisch erfassen, Links folgen und die Inhalte in maschinenlesbaren Formaten wie JSON ausgeben. Es eignet sich besonders, wenn größere Datenmengen aus verschiedenen Quellen gesammelt und vereinheitlicht werden sollen – etwa für KI-Anwendungen, SEO-Analysen oder Wissensdatenbanken.
SerpAPI hingegen ist auf das Scrapen von Suchmaschinenergebnissen spezialisiert. Es ermöglicht, Google- (oder Bing-, Baidu-, YouTube-) Ergebnisse automatisiert abzurufen und strukturiert zurückzugeben – inklusive Titel, URLs, Snippets, Bewertungen oder Rich Results. Damit entfällt das aufwendige Parsen von Suchergebnisseiten, die sich zudem häufig in ihrer Struktur ändern.
Beide Tools bieten stabile APIs, unterstützen hohe Abrufraten und sind auf Zuverlässigkeit trotz Anti-Scraping-Maßnahmen ausgelegt. Sie eignen sich daher ideal für Projekte, bei denen Datenqualität, Skalierbarkeit und Wartungsfreundlichkeit im Vordergrund stehen.
Datenauswertung
Bei allen Inhalten, die heute automatisiert gescrapt werden können, stellt sich die Frage: Wie können diese Daten anschließend sinnvoll ausgewertet werden?
Je stärker der Output standardisiert und strukturiert ist, desto besser lassen sich klassische Analyseverfahren oder regelbasierte Algorithmen darauf anwenden.
Ist der Output jedoch unstrukturiert, kontextabhängig oder muss interpretiert werden, können Large Language Models (LLMs) oder KIs wie Claude Sonnet 4 oder OpenAI GPT-5 eingesetzt werden. Diese Modelle sind in der Lage, Texte nicht nur zu analysieren, sondern auch semantisch zu verstehen und zu bewerten. Dadurch entsteht eine intelligente Form der Datenauswertung, bei der nicht nur Schlagworte, sondern auch Bedeutungen, Zusammenhänge und Stimmungen erkannt werden.
Wichtig ist jedoch, darauf zu achten, dass man der KI keine komplett ungefilterten, gescrapten Seiten zur Verfügung stellt, denn jeder Input-Token verursacht Kosten. In kleinem Maßstab sind diese Kosten zwar marginal, können jedoch schnell ansteigen, je umfangreicher und häufiger LLMs eingesetzt werden.
Bei dem aktuellsten Modell von Anthropic (Claude Sonnet 4.5) liegen die Kosten für 1 Million Input-Tokens bei etwa 10 € bis 15 €, abhängig von der Länge und Struktur der Prompts. Im Durchschnitt entsprechen rund 4 Zeichen einem Token, was einer groben Faustregel von 0,75 Tokens pro Wort entspricht.
1 Million Input-Tokens entsprechen somit ungefähr einem Textumfang von rund 770 000 Wörtern.
Ein ähnliches Kostenmodell gilt für Output-Tokens, allerdings ist deren Anzahl stark vom Prompt abhängig. In der Praxis fallen die generierten Tokens meist deutlich geringer aus als die Eingabe und wirken sich daher kostenmäßig nur geringfügig aus.
Workflow
Wir können nun einen beispielhaften Workflow betrachten, der in der folgenden Abbildung dargestellt ist.
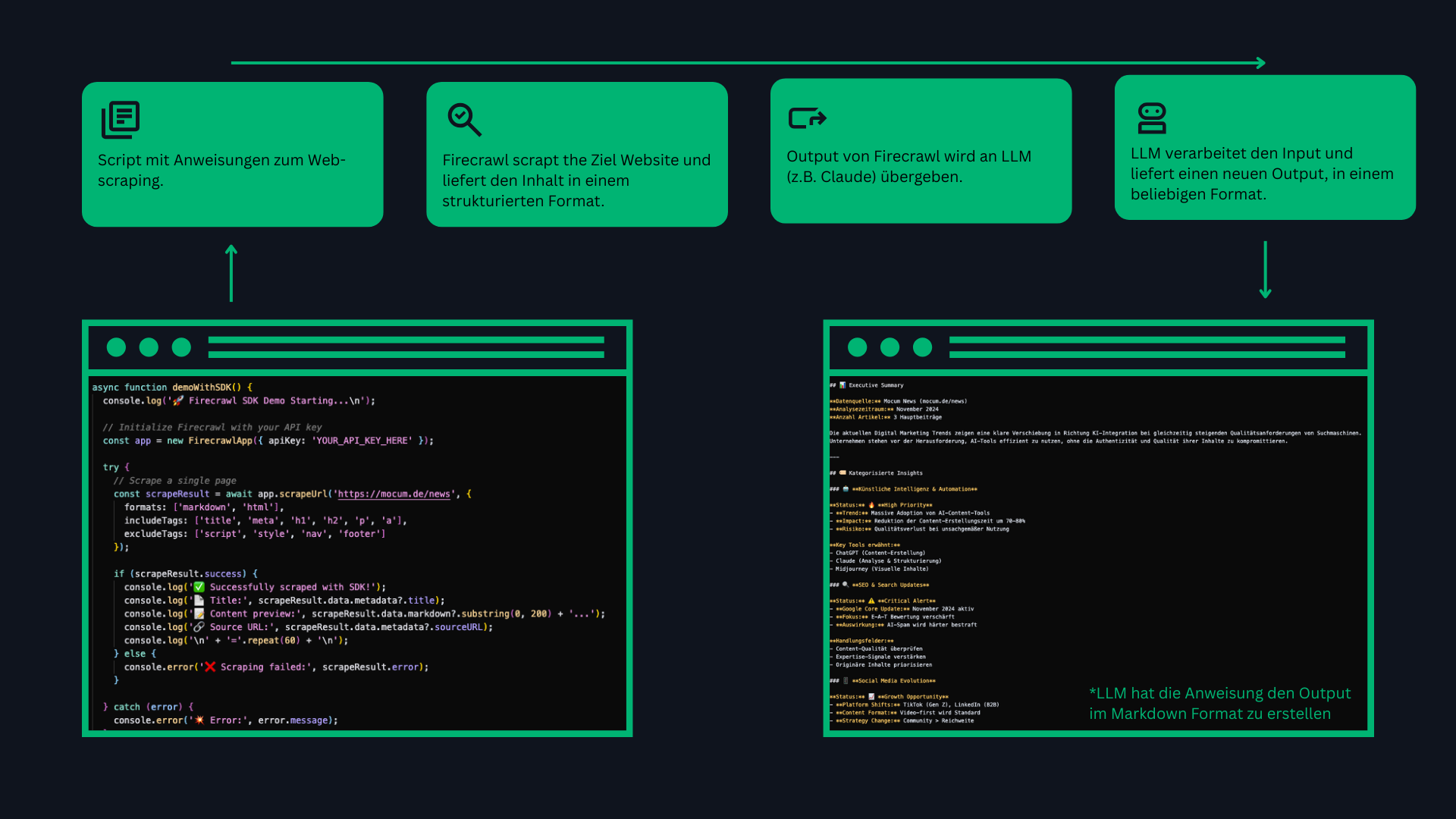
Dieser Workflow ist selbstverständlich noch recht statisch und grundlegend, soll aber zunächst als Veranschaulichung dienen. Im nächsten Schritt kann der Output des LLMs weiterverarbeitet werden und z.B. auf einer Website visualisiert werden. Dafür bieten sich ebenfalls strukturierte Ausgabeformate wie JSON oder XML an.
Auch das Scraping-Verfahren selbst lässt sich intelligenter gestalten. So bietet Firecrawl beispielsweise die Möglichkeit, eine Google-Suche zu integrieren, die wiederum mithilfe eines LLMs für eine semantisch intelligentere Informationssuche genutzt werden kann.
Fazit
Unser Fazit zum Thema Web-Scraping in Kombination mit KI fällt sehr positiv aus. Der entscheidende Unterschied zu früheren Methoden wie cURL besteht darin, dass man nun dank KI ein völlig neues Level an Intelligenz und Automatisierung erreicht. Jede einzelne Phase des Scraping-Prozesses lässt sich heute intelligent und adaptiv gestalten – stupides Web-Scraping war gestern.
Hinzu kommen moderne Tools wie Firecrawl und SerpAPI für spezialisierte Anwendungen, aber auch etablierte Frameworks wie Scrapy für umfassende Scraping-Projekte oder Browser-Automatisierungs-Tools wie Puppeteer und Playwright für JavaScript-lastige Websites. Diese Vielfalt an Werkzeugen macht Web-Scraping aus Anwenderperspektive noch einfacher und zugänglicher. Damit ist Web-Scraping keine technische Hürde mehr, sondern vor allem eine Frage der Idee und des Anwendungsziels.
Das Feld hat zweifellos eine neue Entwicklungsstufe erreicht.
Was hältst du zum Beispiel von einem intelligenten Research-Agenten, der dir automatisch die wichtigsten Artikel zusammenstellt?
Es gibt zahlreiche Einsatzmöglichkeiten für KI-gestützte Scraper – woran denkst du? Schreib uns!